In this article, we’ll learn Some basic concepts of client, server, web services & components.
What is Client, Server, and Host?
What is a Client?
A client is a computer hardware device or software that accesses a service made available by a server. The
server is often (but not always) located on a separate physical computer.
What is a Server?
A server is a physical computer dedicated to running services to serve the needs of other computers. Depending on the service that is running, it could be a file server, database server, home media server, print server, or web server.

What is a Host?
A host is a computer, connected to other computers for which it provides data or services over a network. In theory, every computer connected to a network acts as a host to other peers on the network. In essence, a host reflects the logical relationship of two or more computers on a network. Let’s say, a user wants to download an image from another computer from his network. That computer is “hosting” the image and therefore, it is the host computer. On the other hand, if that same computer downloads an image from the user’s computer, then the user’s computer becomes the host computer. The user computer can be a host to other computers. Likewise, a user router can be a host to other routers. But a host must have an assigned IP address.
Therefore, modems, hubs, and switches are not considered hosts because they do not have assigned IP addresses.
What is a hostname and host ID?
The hostname is the name of the computer.
The host ID is the physical address (the MAC address of the Network Interface Controller).
What is the Client-Server Model?
The client-server model, or client-server architecture, is a distributed application framework dividing tasks
between servers and clients, which either reside in the same system or communicate through a computer
network or the Internet. The client relies on sending a request to another program in order to access a
service made available by a server. The server runs one or more programs that share resources with and
distribute work among clients.
The client-server relationship communicates in a request–response messaging pattern and must adhere to a common communications protocol, which formally defines the rules, language, and dialog patterns to be used. Client-server communication typically adheres to the TCP/IP protocol suite. TCP protocol maintains a connection until the client and server have completed the message exchange. TCP
protocol determines the best way to distribute application data into packets that networks can deliver,
transfers packets to and receives packets from the network, and manages flow control and retransmission of dropped or garbled packets. IP is a connectionless protocol in which each packet traveling through the
The Internet is an independent unit of data unrelated to any other data units. Client requests are organized and prioritized in a scheduling system, which helps servers cope with the instance of receiving requests from many distinct clients in a short space of time. The client-server approach enables any general-purpose computer to expand its capabilities by utilizing the shared resources of other hosts. Popular client-server applications include email, the World Wide Web, and network printing.
Client Server Architecture
There are four main categories of client-server computing:
One-Tier architecture:
where Data and Applications reside in one machine. Presentation, Business, and Data Access layers within a single software package. The data is usually stored in the local system or a shared drive. Applications such as MS Office come under the one-tier application.

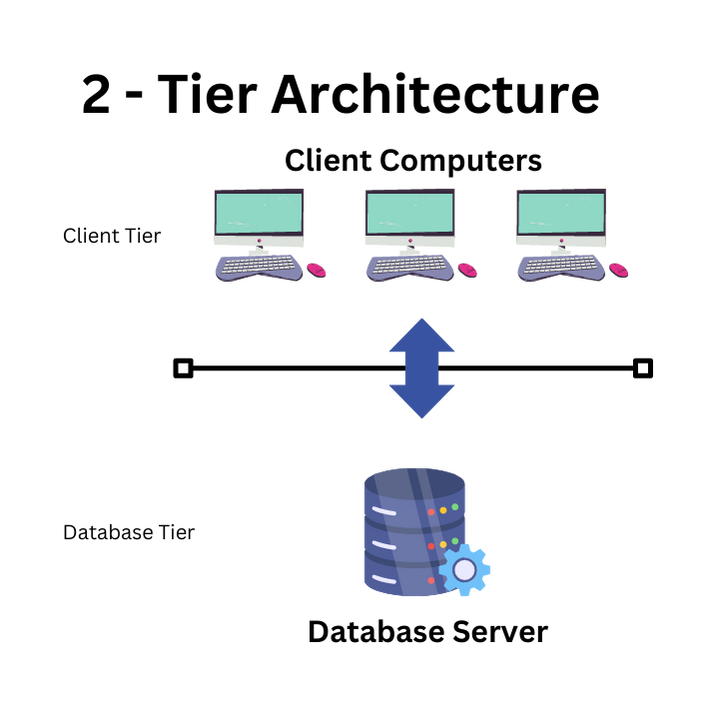
Two-Tier architecture:
where the Client resides in one system and the database server is in another system. Users can have multiple clients. For instance, online ticket reservations software uses the two-tier architecture. The client-server GUI is written in high-level languages such as C++ and Java.
Three-Tier architecture:
In 3 tier architecture, users need the Internet. This is applicable mainly to web applications. We have client
(Browser), DB server (where we store our data). In between the client and server, there is the business logic layer (which is called a middle layer).
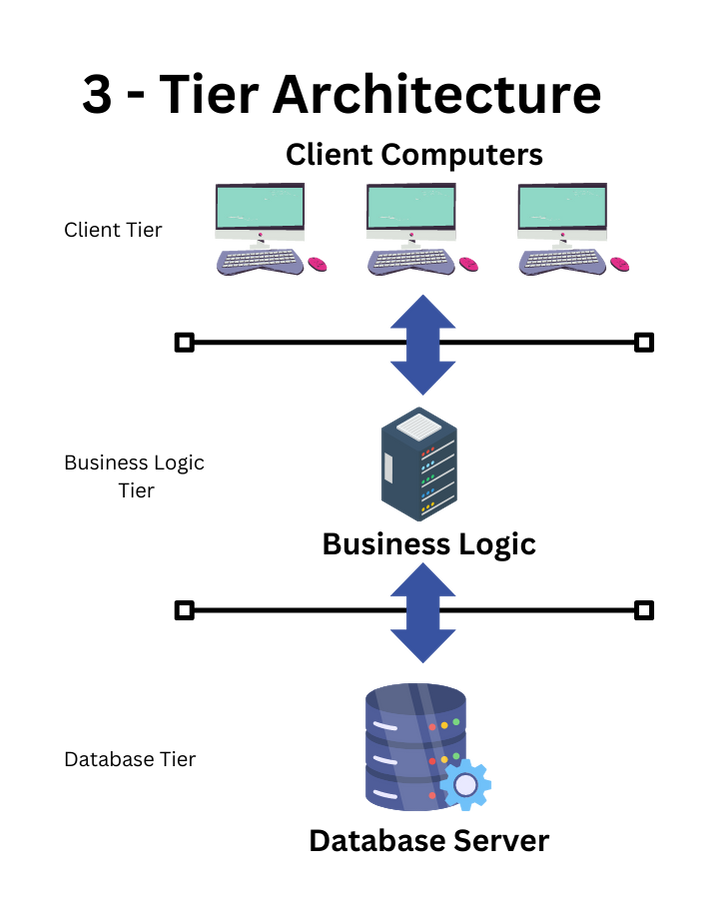
So, we have 3 layers here:
- Client layer/Client Server/Presentation Layer/UI (Front End)
- Application layer/Application server/Web server (Business Logic)
- Database Layer/Database server (Back End)
N-Tier architecture:
divides an application into logical layers, which separate responsibilities and manage dependencies, and physical tiers, which run on separate machines, improve scalability, and add latency from the additional network communication. N-Tier architecture can be closed-layer, in which a layer can only communicate with the next layer down, or open-layer, in which a layer can communicate with any layers below it.
Web Services & its Components
Web Services
So, web services are any bit of service that makes it accessible over the Internet and normalizes its correspondence through XML encoding. A customer conjures web services by sending a solicitation (for the most part as an XML message), and the services send back an XML response. Web services summon communication over a network, with HTTP as the most widely recognized method for the network between the two frameworks. Web services are equivalent to SOA (Services Oriented Architecture) and fundamentally depend on measures, for example, XML-RPC and SOAP (Simple Object Access Protocol).
Components
All the standard web services work using the following components.
SOAP (Simple Object Access Protocol)
UDDI (Universal Description, Discovery, and Integration)
WSDL (Web Services Description Language)
Web APIs: API stands for Application Programming Interface. It is a collection of communication conventions and subroutines used by various programs to communicate between them. A developer can utilize different API apparatuses to make its program simpler and less complex. Likewise, an API encourages the developers with a proficient method to build up their product programs. Thus, in simple terms, an API determines how programming segments ought to associate with one another. It is a set of protocols and schedules, and its reactions are returned as JSON or XML in data. APIs can utilize any kind of communication convention and are not restricted similarly to a web service.
KEY difference between API and Web Service
- Web service is a collection of open-source protocols and standards used for exchanging data between systems or applications whereas API is a software interface that allows two applications to interact with each other without any user involvement.
- It is used for REST, SOAP, and XML-RPC for communication while API is used for any style of communication.
- Web service supports only HTTP protocol whereas API supports HTTP/HTTPS protocol.
- Web service supports XML while API supports XML and JSON.
- All Web services are APIs but all APIs are not web services.
HTTP vs HTTPS
What is HTTP?
TTP stands for Hyper Text Transfer Protocol. At its most basic it allows for communication between different systems. It’s most commonly used to transfer data from a web server to a browser in order to allow users to view web pages. It’s the protocol that was used for basically all early websites.
What is HTTPS?
HTTPS stands for Hypertext Transfer Protocol Secure. The HTTP protocol is not secure protocol as it does not contain SSL (Secure Sockets Layer), which means that the data can be stolen when the data is transmitted from the client to the server. Whereas, the HTTPS protocol contains the SSL certificate that converts the data into an encrypted form, so no data can be stolen in this case as outsiders do not understand the encrypted text.
To know more, you may also see, HTTP Fundamentals.
What is URI and URL?
Uniform Resource Identifier (URI) is a sequence of characters that distinguishes one resource from
another.
There are two types of URIs:
- URNs : Uniform Resource Name (URN) is a persistent and location-independent identifier.
- URLs : Uniform Resource Locator (URL) is a specific type of identifier that not only identifies the resource but tells you how to access it or where it’s located.
The key difference between URIs and URLs is that URIs are identifiers, whereas URLs are locators. In
other words, a URI simply identifies the resource. It does not describe or imply how to locate the
resource. A URL does.
The most common analogy used to understand the difference between URIs and URLs is comparing a
person’s name vs. their address. A person’s name is like a URI because it identifies the person without
providing any information on how to locate them. An address, however, identifies the person as
a resident of that address and provides their physical location. That’s why it’s like a URL.